在职研究生
摘要:在当前数字化时代,会议纪要的生成已经成为了组织高效运作的一个重要环节。随着人工智能技术的迅速发展,大语言模型已经在自然语言处理领域展示了显著的潜力。本文聚焦于探讨如何利用大语言模型生成高质量的会议纪要,以提升会议效率、降低人力成本,并提高文档处理的准确性和专业性。本文介绍了大语言模型的基本原理和功能,特别是它们在理解和生成自然语言方面的能力。描述了大语言在会议纪要生成流程,模型训练的关键动作,利用大语言模型生成会议纪要的优势与局限性以及对的展望。
关键词:大语言模型、会议纪要、模型训练、语言处理
一、引言
会议在企业、政府、学术机构等组织的决策、交流和协调过程中扮演着至关重要的角色。它们是信息交流、观点碰撞、共识形成的平台,对组织的战略方向和日常运作具有深远影响。然而,传统的会议纪要撰写过程中存在着诸多挑战:首先,人力资源的投入大。传统的会议纪要通常需要会议记录员或相关人员在会议进行时进行记录,或在会议结束后通过录音回放来撰写,这一过程耗时且费力。其次,会议纪要的质量参差不齐。由于撰写人员的专业水平、理解能力和记录风格的不同,会议纪要的准确性和专业性常常难以保证。为了解决这些问题,本文提出了一种解决方案:利用大语言模型自动生成会议纪要。大语言模型作为一种先进的自然语言处理工具,具备强大的语言理解和生成能力,能够从大量文本中学习语言的模式和结构。通过将会议的录音转换为文字,并输入到经过专门训练的大语言模型中,可以自动生成结构化、清晰、准确的会议纪要。这种方法不仅可以大幅度减少人力和时间成本,还能提高会议纪要的质量,保证信息的一致性和专业性。此外,本文还将探讨大语言模型在会议纪要生成中的应用过程、优势、挑战以及未来的发展潜力。我们希望通过这项研究,为企业、政府和学术机构等提供一种高效、准确、经济的会议纪要解决方案,从而促进这些组织的信息管理和决策效率。
二、大语言模型概述
大语言模型是一种基于深度学习的自然语言处理技术,作为基于深度学习的自然语言处理(NLP)技术的前沿成果,可以自动分析、理解、生成自然语言文本,通过分析大量文本数据,学习语言的复杂模式和结构,从而能够以惊人的准确性和流畅性处理和生成语言。与传统的机器翻译技术相比,大语言模型具有更强的语义理解和生成能力,可以更好地处理自然语言文本的复杂性和歧义性。首先,它们在语义理解方面表现更为出色。这些模型不仅能够识别和解释单词和短语的字面意义,还能够捕捉语境中的隐含意义,理解复杂的语言结构和语义关系。其次,大语言模型在生成能力上也有显著优势。它们能够生成连贯、逻辑一致、与上下文紧密相关的文本,这在处理自然语言文本的复杂性和歧义性方面尤为重要。这些模型通常采用基于Transformer的架构,这是一种高效的深度学习网络结构,特别适合处理长距离的依赖关系。此外,大语言模型的训练过程涉及到从海量文本数据中学习,这包括来自书籍、文章、网站等多种类型的文本。通过这种广泛的学习,模型能够理解各种语言风格和表达形式,从而在生成文本时表现出更高的灵活性和适应性。大语言模型的性能在很大程度上依赖于其训练数据的质量和多样性。因此,模型训练的过程中,确保数据的全面性和代表性是至关重要的。同时,这些模型的高性能也带来了较高的计算资源需求,因此在实际应用中需要权衡性能与资源消耗之间的关系。
三、会议流程纪要
3.1 大语言模型会议纪要生成流程
会议纪要的生成流程是一个结合了人工智能技术和人工审核的复合流程,旨在提高会议纪要的生成效率和质量。以下是详细的步骤:
3.2
大语言模型会议纪要使用流程
使用过程如图1所示,以下是详细步骤:
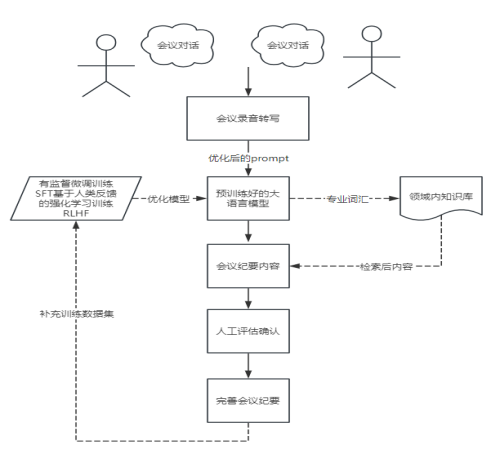
图1 大语言模型会议纪要使用流程图
3.3 大语言模型训练
大语言的模型的训练对于生成会议纪要至关重要,以下对几个关键性模型训练动作展开描述:
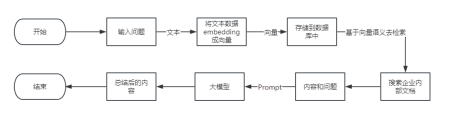
图2领域知识专业库使用流程图
输入问题到转换成文本,通过文本数据embedding成向量,存储到数据库中,然后基于向量语义去检索和问题有关的内容,将得到的内容和问题作为prompt给到大模型,大模型再返回一个总结性的内容。
一、会议信息
会议主题:${meetingSubject}
会议时间:${meetingStartTime} - ${meetingEndTime}
会议地点:${meetingLocation}
预定人:${reserver}
参会人员:${conferee}
二、会议内容记录
${meetingSource}
三、会议总结
${meetingSummary}
四、会议结论及下一步计划
${meetingTasks}
图3提示词优化流程图
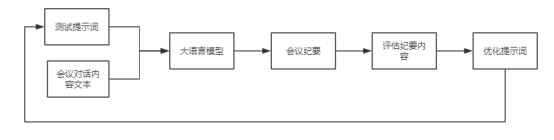

图4大语言模型预训练流程图
四、大语言模型的优势与局限性
利用大语言模型生成会议纪要具有以下优势:
然而,利用大语言生成会议纪要也存在一些局限性:
五、未来展望
虽然大语言模型在会议纪要生成方面已经取得了一定的成果,但仍然存在一些挑战和问题需要进一步研究和解决。未来研究可以关注以下几个方面:
1.提高模型的语义理解能力:当前的大语言模型虽然在表面文本的处理上表现出色,但在处理复杂的语言结构和深层次语义关系时仍有局限。未来的研究需要关注如何进一步提升模型的语义理解能力,使其能更准确地捕捉会议内容中的逻辑关系和深层含义。这包括对复杂的语言现象、如隐喻、专业术语的理解,以及更好的上下文关系分析。
2.跨领域适应性:不同领域和行业的会议具有不同的语言风格和专业知识需求。因此,开发能够跨领域适应并精准应对各种专业领域需求的模型是未来的关键。这不仅要求模型能够适应不同的语言风格,还要求其能够理解和运用特定领域的专业知识。
3.隐私保护和信息安全:在利用大语言模型生成会议纪要的过程中,涉及用户隐私和敏感信息的处理是一个重要问题。未来的研究需要着重于如何在不影响模型性能的前提下,保护用户隐私和确保信息安全,包括对敏感数据的加密处理、匿名化处理及其它防护措施。
4.可解释性和透明度:大语言模型的黑盒特性使得其决策过程和结果难以解释和透明,这在一定程度上限制了用户对模型决策的信任和理解。提高模型的可解释性和透明度,使用户能够更清楚地理解模型如何做出决策,是提升模型可用性和用户接受度的关键。
参考文献
[1]韩旭;张正彦;刘知远.知识指导的预训练语言模型[J].中兴通讯技术
[2]李闻一.财务共享服务中心的大语言模型应用探究[J].会计之友,2023
[3]张宏玲;沈立力;韩春磊;付雅明.大语言模型对图书馆数字人文工作的挑战及应对思考[J].图书馆杂志
[4]潘囿丞;侯永帅;杨卿;余跃;相洋.大规模语言模型的跨云联合训练关键技术[J].中兴通讯技术
[5]徐月梅;胡玲;赵佳艺;杜宛泽;王文清.大语言模型的技术应用前景与风险挑战[J]. 计算机应用
[6]舒文韬;李睿潇;孙天祥;黄萱菁;邱锡鹏.大型语言模型:原理、实现与发展[J].计算机研究与发展
[7]韩毅;乔林波;李东升;廖湘科.知识增强型预训练语言模型综述[J]. 计算机科学与探索
[8]Zhou Yu Jia;Yao Jing;Dou Zhi Cheng;Wu Ledell;Wen Ji Rong.DynamicRetriever: A Pre-trained Model-based IR System Without an Explicit Index[J]. Machine Intelligence Research,2023
[9]严豫;杨笛;尹德春.融合大语言模型知识的对比提示情感分析方法[J]. 情报杂志,2023
[10]罗鹏程;王一博;王继民.基于深度预训练语言模型的文献学科自动分类研究[J]. 情报学报,2020
[11]GPT型技术应用重塑数字人文探讨[J]. 王静静;洪贇;叶鹰.情报理论与实践,2023(06)
刘鑫,1990年04月18日出生,男,2012年本科毕业于天津工业大学,籍贯:天津市滨海新区,现居北京。在职研究生专业是计算机应用技术。

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



